









21-02
2021
[Poster]
[Poster]
CharminG: A Scalable GPU-resident Runtime System [HPDC 2021]
19-06
2019
[Poster]
[Poster]
ACM SRC: Fast Profiling-based Performance Modeling of Distributed GPU Applications [SC 2019]
18-01
2017
[Talk]
[Talk]
Optimizing Point-to-Point Communication between Adaptive MPI Endpoints in Shared Memory [ExaMPI 2017]
17-11
2017
[Poster]
[Poster]
ACM SRC: Runtime Support for Concurrent Execution of Overdecomposed Heterogeneous Tasks [SC 2017]
17-06
2017
[Poster]
[Poster]
Adaptive MPI: Dynamic Runtime Support for MPI Applications [EuroMPI 2017]
17-01
2017
[Poster]
[Poster]
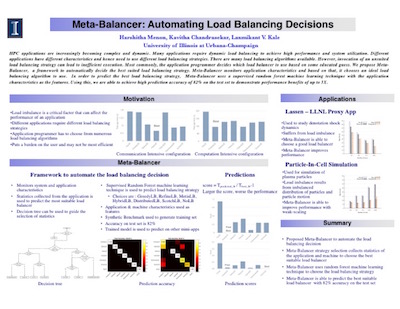
Poster: Automated Load Balancer Selection Based on Application Characteristics [PPoPP 2017]
{kind=link}
{kind=link}
16-21
2016
[Poster]
[Poster]
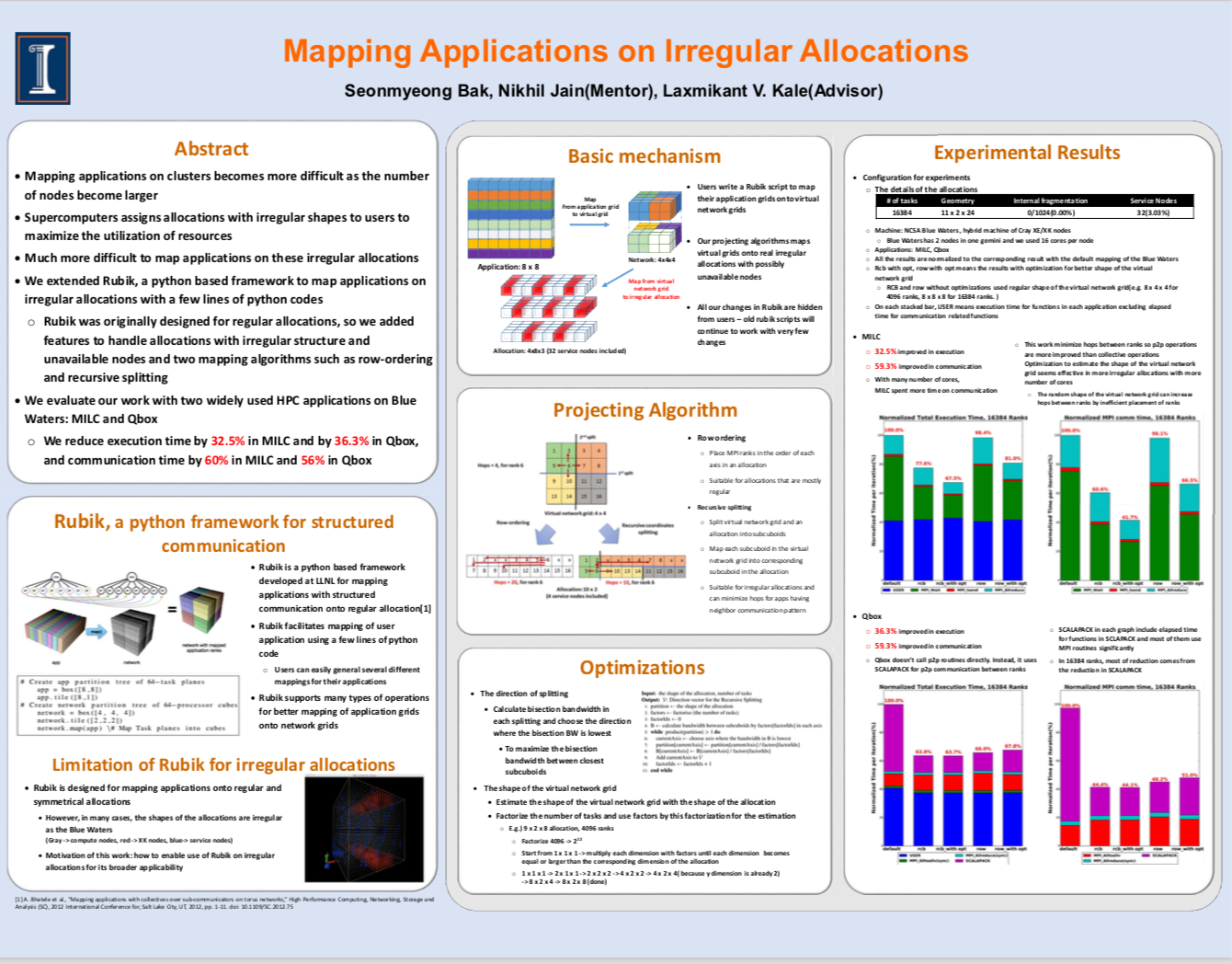
ACM SRC: Mapping Applications on Irregular Allocations [SC 2016]
{kind=link}
16-16
2016
[Talk]
[Talk]
Optimizing Molecular Dynamics and Stencil mini-applications for Intel’s Knights Landing [IXPUG SC BOF 2016]
16-09
2016
[Talk]
[Talk]
Adaptive MPI: Overview & Recent Work [Charm++ Workshop 2016]
16-07
2015
[Talk]
[Talk]
Introducing Over-decomposition to Existing Applications: A Case Study with PlasComCM and Adaptive MPI [Charm++ Workshop 2015]
16-06
2016
[Talk]
[Talk]
Charm++ and AMPI [WEST 2016]
15-21
2015
[Talk]
[Talk]
Charm++ Motivations and Basic Ideas [ATPESC 2015]
15-20
2015
[Talk]
[Talk]
Charm++ Overview and suggestions for collaborations [JLESC 2015]
15-18
2015
[Talk]
[Talk]
Keynote Talk - Efficient High Performance Computing in the Cloud [VTDC 2015]
15-17
2015
[Talk]
[Talk]
Charm++ & MPI: Combining the Best of Both Worlds [IPDPS 2015]
15-13
2015
[Talk]
[Talk]
Analyzing Energy-Time Tradeoff in Power Overprovisioned HPC Data Centers [HPPAC 2015]
15-09
2015
[Talk]
[Talk]
Energy-efficient Computing for HPC Workloads on Heterogeneous Manycore Chips [PMAM 2015]
15-08
2014
[Poster]
[Poster]
Scalable Trace-driven Parallel Network Simulation [LLNL Poster Symposium 2014]
15-07
2015
[Poster]
[Poster]
Split-and-Merge Method for Accelerating Convergence of Stochastic Linear Programs [ICORES 2015]
14-49
2014
[Talk]
[Talk]
Adaptive runtime systems for computational chemistry [ACS 2014]
14-48
2014
[Talk]
[Talk]
The Charm++ Applications Experience: Production Use of an Asynchronous, Adaptive Runtime [PPSC 2014]
14-47
2014
[Talk]
[Talk]
Charm++ [ATPESC 2014]
14-46
2014
[Talk]
[Talk]
An automatic control system for runtime adaptivity [JLESC 2014]
14-45
2014
[Talk]
[Talk]
Temperature, Power and Energy: How an Adaptive Runtime can optimize them [JLESC 2014]
14-44
2014
[Talk]
[Talk]
Advanced Techniques in Parallel Performance Analysis [JLESC 2014]
14-43
2014
[Talk]
[Talk]
Tutorial: Identifying bottleneck in applications [JLPC 2014]
14-42
2014
[Talk]
[Talk]
The Need for Well-Factored Dynamic Parallel Programming Systems, and Why Charm++ is a Good Choice [No Conference 2014]
14-40
2014
[Talk]
[Talk]
Maximizing Throughput on a Dragonfly Network [SC 2014]
14-38
2014
[Talk]
[Talk]
Power Aware Resource Manager [SC 2014]
14-37
2014
[Talk]
[Talk]
PICS - A Performance-analysis-based Introspective Control System to Steer Parallel Applications]{PICS - a Performance-analysis-based Introspective Control System to Steer Parallel Applications [No Conference 2014]
14-36
2014
[Talk]
[Talk]
Optimizing Data Locality for Fork/Join Programs Using Constrained Work Stealing [SC 2014]
14-31
2014
[Talk]
[Talk]
Scalable Replay with Partial-Order Dependencies for Message-Logging Fault Tolerance [Cluster 2014]
14-16
2014
[Talk]
[Talk]
Applications using Charm++ (X-Stack PIs meeting) [No Conference 2014]
14-11
2014
[Poster]
[Poster]
Parallel Algorithms for Two-stage Stochastic Integer Optimization [IPDPS PhD Forum 2014]
14-09
2014
[Talk]
[Talk]
Getting Ready for Adaptive RTSs [Salishan 2014]
14-08
2014
[Talk]
[Talk]
Parallel Branch-and-Bound for Two-stage Stochastic Integer Optimization [Charm++ Workshop 2014]
14-06
2014
[Talk]
[Talk]
Power-aware Job Scheduling: Maximizing Data Center Performance Under a Strict Power Budget [Charm++ Workshop 2014]
14-05
2014
[Poster]
[Poster]
An Optimal Distributed Load Balancing Algorithm for Homogeneous Work Units [ICS 2014]
13-65
2013
[Talk]
[Talk]
ACR: Automatic Checkpoint/Restart for Soft and Hard Error Protection [JLPC 2013]
13-64
2013
[Talk]
[Talk]
Dynamic Load Balancing for Weather Models via AMPI [JLPC 2013]
13-63
2013
[Talk]
[Talk]
A Multi-resolution Emulation + Simulation Methodology for Exascale [JLPC 2013]
13-62
2013
[Talk]
[Talk]
Acceleration of an Asynchronous Message Driven Programming Paradigm on IBM Blue Gene/Q [IPDPS 2013]
13-59
2013
[Talk]
[Talk]
LRTS: A Portable High Performance Low-level Communication Interface [Charm++ Workshop 2013]
13-58
2013
[Poster]
[Poster]
Scalable and Asynchronous Algorithms for Structured Adaptive Mesh Refinement [HiPC 2013]
13-57
2013
[Talk]
[Talk]
Parallel Branch-and-Bound for Two-stage Stochastic Integer Optimization (Best Paper Award) [HiPC 2013]
13-55
2013
[Talk]
[Talk]
Performance Optimization Under Thermal and Power Constraints For High Performance Computing Data Centers [Thesis 2013]
13-54
2013
[Talk]
[Talk]
ERS: Techniques for Improving Observed Network Performance [SC 2013]
13-53
2013
[Poster]
[Poster]
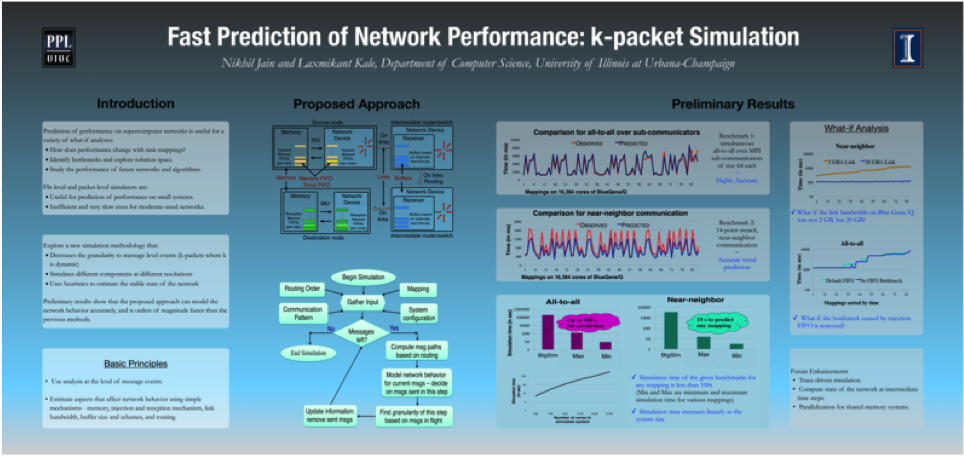
Fast Prediction of Network Performance: k-packet Simulation [SC 2013]
{kind=link}
13-52
2013
[Poster]
[Poster]
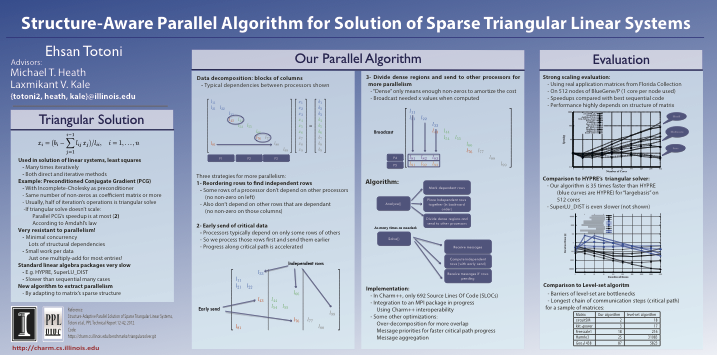
ACM SRC: Structure-Aware Parallel Algorithm for Solution of Sparse Triangular Linear Systems [SC 2013]
{kind=link}
13-50
2013
[Talk]
[Talk]
A ‘Cool’ Way of Improving the Reliability of HPC Machines [SC 2013]
13-49
2013
[Talk]
[Talk]
ACR: Automatic Checkpoint/Restart for Soft and Hard Error Protection [SC 2013]
13-48
2013
[Talk]
[Talk]
Predicting Application Performance using Supervised Learning on Communication Features [SC 2013]
13-47
2013
[Talk]
[Talk]
A Distributed Dynamic Load Balancer for Iterative Applications [SC 2013]
13-35
2013
[Poster]
[Poster]
Steal Tree: Low-Overhead Tracing of Work Stealing Schedulers [PLDI 2013]
{kind=link}
13-34
2013
[Talk]
[Talk]
Projections: Scalable Performance Analysis and Visualization [VAPLS 2013]
13-32
2013
[Talk]
[Talk]
Keynote: The Coming Era of Adaptive Control Systems in HPC [ICPP 2013]
13-31
2013
[Poster]
[Poster]
Towards Efficient Mapping, Scheduling, and Execution of HPC Applications on Platforms in Cloud [IPDPS PhD Forum 2013]
13-28
2012
[Poster]
[Poster]
Understanding Network Contention on Blue Gene Supercomputers [LLNL Poster Symposium 2012]
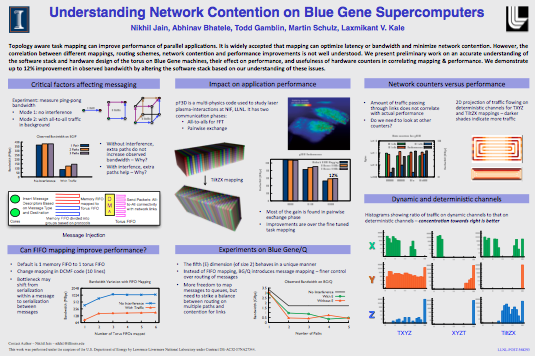{kind=link}
13-27
2013
[Poster]
[Poster]
Chizu: A Framework to Enable Topology Aware Task Mapping [LLNL Poster Symposium 2013]
13-23
2013
[Talk]
[Talk]
Tutorial: Programming with Parallel Migratable Objects [ATPESC 2013]
13-15
2012
[Talk]
[Talk]
Collectives on Two-tier Direct Networks [EuroMPI 2012]
13-14
2013
[Talk]
[Talk]
Charm++ Interoperability [Charm++ Workshop 2013]
13-13
2013
[Talk]
[Talk]
Predicting Application Performance using Supervised Learning on Communication Features [Lawrence Livermore Talk 2013]
13-12
2013
[Talk]
[Talk]
Steal Tree: Low-Overhead Tracing of Work Stealing Schedulers [PLDI 2013]
13-11
2013
[Talk]
[Talk]
Characteristics of Adaptive Runtime Systems in HPC [ROSS 2013]
13-10
2013
[Talk]
[Talk]
Toward Runtime Power Management of Exascale Networks by On/Off Control of Links [HPPAC 2013]
13-06
2013
[Talk]
[Talk]
Adoption Protocols for Fanout-Optimal Fault-Tolerant Termination Detection [PPoPP 2013]
13-03
2013
[Poster]
[Poster]
Charm++: Migratable Objects + Active Messages + Adaptive Runtime = Productivity + Performance [PSAAP Site-visit 2013]
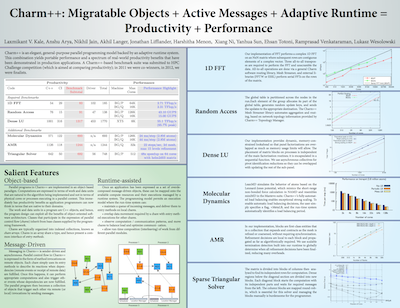{kind=link}
13-02
2013
[Poster]
[Poster]
Scalable Algorithms for Distributed-Memory Adaptive Mesh Refinement [PSAAP Site-visit 2013]
12-61
2012
[Talk]
[Talk]
Programming model needs at NCSA and ANL [JLPC 2012]
12-60
2012
[Talk]
[Talk]
Charj: compiler supported language with an adaptive runtime [JLPC 2012]
12-59
2012
[Talk]
[Talk]
The recovery and rise of checkpoint/restart [JLPC 2012]
12-58
2012
[Talk]
[Talk]
Fault tolerance needs at NCSA and ANL [JLPC 2012]
12-57
2012
[Talk]
[Talk]
Charm++ update [JLPC 2012]
12-56
2012
[Talk]
[Talk]
A perspective on the BigSim approach to performance prediction [JLPC 2012]
12-55
2012
[Talk]
[Talk]
Fernbach Acceptance - NAMD [SC 2012]
12-53
2012
[Talk]
[Talk]
Automated Load Balancing Invocation based on Application Characteristics [Cluster 2012]
12-52
2012
[Poster]
[Poster]
Work Stealing and Persistence-based Load Balancers for Iterative Overdecomposed Applications [HPDC 2012]
12-51
2012
[Talk]
[Talk]
Scalable Algorithms for Distributed-Memory Adaptive Mesh Refinement [SBAC-PAD 2012]
12-49
2012
[Talk]
[Talk]
Performance Optimization of a Parallel, Two Stage Stochastic Linear Program: The Military Aircraft Allocation Problem [ICPADS 2012]
12-48
2012
[Talk]
[Talk]
Optimizing Fine-grained Communication in a Biomolecular Simulation Application on Cray XK6 [SC 2012]
12-43
2012
[Talk]
[Talk]
Assessing Energy Efficiency of Fault Tolerance Protocols for HPC Systems [SBAC-PAD 2012]
12-40
2012
[Talk]
[Talk]
Scalable Algorithms for Constructing Balanced Spanning Trees on System-ranked Process Groups [EuroMPI 2012]
12-34
2012
[Talk]
[Talk]
A Scalable Double In-memory Checkpoint and Restart Scheme towards Exascale [FTXS 2012]
12-30
2012
[Talk]
[Talk]
A Message-Logging Protocol for Multicore Systems [FTXS 2012]
12-26
2012
[Talk]
[Talk]
A uGNI-Based Asynchronous Message-Driven Runtime System for Cray Supercomputers with Gemini Interconnect [IPDPS 2012]
12-25
2012
[Talk]
[Talk]
Work Stealing and Persistence-based Load Balancers for Iterative Overdecomposed Applications [HPDC 2012]
12-24
2012
[Talk]
[Talk]
Dynamic Scheduling for Work Agglomeration on Heterogeneous Clusters [Workshop on Multicore and GPU Programming Models, Languages and Compilers at IPDPS 2012]
12-23
2012
[Talk]
[Talk]
Mapping Dense LU Factorization on Multicore Supercomputer Nodes [IPDPS 2012]
12-16
2012
[Talk]
[Talk]
Charm++ Tutorial for UIUC SIAM [Charm++ Workshop 2012]
12-10
2012
[Talk]
[Talk]
Comparing the Power and Performance of Intel’s SCC to State-of-the-Art CPUs and GPUs [ISPASS 2012]
12-09
2012
[Talk]
[Talk]
Composable and Modular Exascale Programming Models with Intelligent Runtime Systems [Sandia Talk 2012]
12-05
2012
[Talk]
[Talk]
Composable Libraries for Parallel Programming [PPSC 2012]
12-01
2012
[Talk]
[Talk]
Performance Issues and Techniques in Scalable Parallel Programming [C-DAC 2012]
11-61
2011
[Talk]
[Talk]
Some progress highlights for Charm++ [JLPC 2011]
11-56
2011
[Talk]
[Talk]
Charm++ Tutorial [ICS 2011]
11-52
2012
[Poster]
[Poster]
Collective Algorithms for Sub-communicators [PPoPP 2012]
{kind=link}
11-48
2011
[Talk]
[Talk]
Charm++ for Productivity and Performance: A Submission to the 2011 HPC Class II Challenge [SC 2011]
11-47
2011
[Talk]
[Talk]
Avoiding Hot-Spots on Two-Level Direct Networks [SC 2011]
11-46
2011
[Talk]
[Talk]
ACM SRC: Optimizing AlltoAll Algorithm for PERCS Network Using Simulation [SC 2011]
11-45
2011
[Talk]
[Talk]
HPC Runtime System Software [SC 2011]
11-44
2011
[Poster]
[Poster]
Optimizing All-to-All Algorithm for PERCS Network Using Simulation [SC 2011]
{kind=link}
11-43
2011
[Poster]
[Poster]
Tune Up for Blue Waters Before it Arrives [Charm++ Workshop 2011]
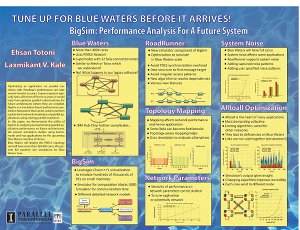{kind=link}
11-42
2011
[Talk]
[Talk]
Large Scale Simulations Enabled by BigSim [Charm++ Workshop 2011]
11-38
2011
[Talk]
[Talk]
Dynamic Load Balance for Optimized Message Logging in Fault Tolerant HPC Applications [Cluster 2011]
11-36
2011
[Talk]
[Talk]
Heuristic-based Techniques for Mapping Irregular Communication Graphs to Mesh Topologies [ESCAPE 2011]
11-33
2011
[Poster]
[Poster]
Enabling Massive Parallelism for Stochastic Optimization [SC 2011]
11-31
2011
[Talk]
[Talk]
Composable and Modular Exascale Programming Models with Intelligent Runtime Systems [ASCR Programming Challenges 2011]
11-20
2011
[Poster]
[Poster]
Scaling NAno Molecular Dynamic(NAMD) on Petascale machines using Charm++ [PPL Talk 2011]
11-19
2011
[Talk]
[Talk]
An Adaptive Framework for Large-scale State Space Search [LSPP 2011]
11-16
2011
[Talk]
[Talk]
Architectural Constraints Required to Attain 1 Exaflop/s for Scientific Applications [IPDPS 2011]
11-15
2011
[Talk]
[Talk]
Techniques for Effective Petascale Application Development based on Adaptive Runtime Systems [PPL Talk 2011]
11-14
2011
[Poster]
[Poster]
Molecular Dynamics Simulations on Supercomputers Performing 10^18 flop/s [UIUC Postdoc Symposium 2011]
10-49
2010
[Talk]
[Talk]
Exascale packages for atomistic simulations from nanoscience to drug design [JLPC 2010]
10-48
2010
[Talk]
[Talk]
Kaapi/Charm++ preliminary comparison [JLPC 2010]
10-47
2010
[Talk]
[Talk]
NUMA support for Charm++ [JLPC 2010]
10-46
2010
[Talk]
[Talk]
Clustering Message Passing Applications to Enhance Fault Tolerance Protocols [JLPC 2010]
10-45
2010
[Talk]
[Talk]
Scaling NAMD into the Petascale and Beyond [JLPC 2010]
10-44
2010
[Talk]
[Talk]
Hierarchical Load Balancing for Charm++ Applications on Large Supercomputers [P2S2 2010]
10-41
2010
[Talk]
[Talk]
A Study of Memory-Aware Scheduling in Message Driven Parallel Programs [HiPC 2010]
10-40
2010
[Talk]
[Talk]
Automated Mapping of Regular Communication Graphs on Mesh Interconnects [HiPC 2010]
10-39
2010
[Talk]
[Talk]
Topology Aware Mapping [PPL Talk 2010]
10-38
2010
[Talk]
[Talk]
Using BigSim to Estimate Application Performance [PPL Talk 2010]
10-37
2010
[Talk]
[Talk]
Clustering Parallel Applications to Enhance Message Logging Protocols [PPL Talk 2010]
10-36
2010
[Talk]
[Talk]
Mapping Your Application on Interconnect Topologies: Effort Versus Benefits [SC 2010]
10-35
2010
[Talk]
[Talk]
Debugging Large Scale Applications in a Virtualized Environment [LCPC 2010]
10-34
2010
[Talk]
[Talk]
Debugging Large Scale Applications with Virtualization [PPL Talk 2010]
10-33
2010
[Talk]
[Talk]
Optimizing a Parallel Runtime System for Multicore Clusters: A Case Study [TeraGrid 2010]
10-32
2010
[Talk]
[Talk]
Mapping Parallel Applications on the Machine Topology: Lessons Learned [TeraGrid 2010]
10-31
2010
[Talk]
[Talk]
Biomolecular Simulations using NAMD on TeraGrid machines [TeraGrid 2010]
10-30
2010
[Talk]
[Talk]
Robust Non-Intrusive Record-Replay with Processor Extraction [PADTAD 2010]
10-29
2010
[Talk]
[Talk]
Team-based Message Logging: Preliminary Results [Resilience 2010]
10-28
2010
[Talk]
[Talk]
Highly Scalable Parallel Sorting [IPDPS 2010]
10-27
2010
[Talk]
[Talk]
Static Macro Data Flow: Compiling Global Control into Local Control [HIPS 2010]
09-34
2009
[Talk]
[Talk]
Scalable Fault Tolerance Schemes using Adaptive Runtime Support [JLPC 2009]
09-33
2009
[Talk]
[Talk]
Programming Methodologies beyond petascale, based on adaptive runtime systems [JLPC 2009]
09-32
2009
[Talk]
[Talk]
Parallel composition and novel programming models [JLPC 2009]
09-29
2009
[Talk]
[Talk]
Techniques in Scalable and Effective Performance Analysis [PPL Talk 2009]
09-28
2009
[Talk]
[Talk]
Automating Topology Aware Task Mapping for Large Supercomputers [SC 2009]
09-27
2009
[Talk]
[Talk]
Adaptive Runtime Support for Fault Tolerance [PPL Talk 2009]
09-26
2009
[Talk]
[Talk]
Scalable Fault Tolerance Schemes Using Adaptive Runtime Support [HPC Resilience Workshop DC 2009]
09-25
2009
[Talk]
[Talk]
Load Balancing and Topology Aware Mapping for Petascale Machines [Scaling to Petascale Summer School 2009]
09-24
2009
[Talk]
[Talk]
A Case Study of Communication Optimizations on 3D Interconnects [Euro-Par 2009]
09-23
2009
[Talk]
[Talk]
Load Balancing Techniques for Asynchronous Spacetime Discontinuous Galerkin Methods [USNCCM 2009]
09-22
2009
[Talk]
[Talk]
Scalable Interaction with Parallel Applications [TeraGrid 2009]
09-21
2009
[Talk]
[Talk]
Dynamic High-Level Scripting in Parallel Applications [IPDPS 2009]
09-20
2009
[Talk]
[Talk]
Dynamic Topology Aware Load Balancing Algorithms for MD Applications [LSPP 2009]
09-19
2009
[Talk]
[Talk]
Object-Based Over-Decomposition Can Enable Powerful Fault Tolerance Schemes [FTXS 2009]
09-18
2009
[Talk]
[Talk]
An Evaluative Study on the Effects of Contention on Message Latencies in Large Supercomputers [LSPP 2009]
09-17
2009
[Talk]
[Talk]
The Charm++ Programming Model and NAMD [BSC 2009]
09-16
2009
[Poster]
[Poster]
Topology Aware Task Mapping Techniques: An API and Case Study [PPoPP 2009]
09-15
2009
[Poster]
[Poster]
Performance Comparison of Intrepid, Jaguar and Ranger using Scientific Applications [SC 2009]
08-30
2008
[Talk]
[Talk]
IS TOPOLOGY IMPORTANT AGAIN? Effects of Contention on Message Latencies in Large Supercomputers [SRC 2008]
08-29
2008
[Talk]
[Talk]
Topology Aware Mapping for Performance Optimization of Science Applications [IACAT 2008]
08-28
2008
[Talk]
[Talk]
Dynamic Topology Aware Load Balancing Algorithms for MD Applications [ICS 2008]
08-27
2008
[Talk]
[Talk]
Preparing for Petascale and Beyond [LAGRID 2008]
08-26
2008
[Talk]
[Talk]
Simplifying Parallel Programming with Incomplete Parallel Languages [UPCRC 2008]
08-25
2008
[Talk]
[Talk]
A Case Study in Tightly-Coupled Multiparadigm Parallel Programming [LCPC 2008]
08-24
2008
[Talk]
[Talk]
Some Essential Techniques for Developing Efficient Petascale Applications [SciDAC 2008]
08-23
2008
[Talk]
[Talk]
Memory Tagging in Charm++ [PADTAD 2008]
08-22
2008
[Talk]
[Talk]
Massively Parallel Cosmological Simulations with ChaNGa [IPDPS 2008]
08-21
2008
[Talk]
[Talk]
Towards Scalable Performance Analysis and Visualization through Data Reduction [IPDPS 2008]
08-20
2008
[Talk]
[Talk]
Application-specific Topology-aware Mapping for Three Dimensional Topologies [LSPP 2008]
08-19
2008
[Talk]
[Talk]
Overcoming Scaling Challenges in Biomolecular Simulations across Multiple Platforms [IPDPS 2008]
08-18
2008
[Poster]
[Poster]
Effects of Contention on Message Latencies in Large Supercomputers [SC 2008]
08-17
2008
[Poster]
[Poster]
Automatic Topology-Aware Task Mapping for Parallel Applications Running on Large Parallel Machines [IPDPS 2008]
07-16
2007
[Talk]
[Talk]
Charisma: Orchestrating Migratable Parallel Objects [HPDC 2007]
06-24
2006
[Talk]
[Talk]
Scalable Cosmological Simulations on Parallel Machines [VECPAR 2006]
06-23
2006
[Talk]
[Talk]
Support for Adaptivity in ARMCI Using Migratable Objects [IPDPS 2006]
06-22
2006
[Talk]
[Talk]
Performance Evaluation of Adaptive MPI [PPoPP 2006]
06-21
2006
[Poster]
[Poster]
Cosmological Simulations on Supercomputers [SC 2006]
06-20
2006
[Poster]
[Poster]
Charm++ on Cell [PPL Poster 2006]
06-19
2006
[Poster]
[Poster]
Charm++ Simplifies Programming for the Cell Processor [SC 2006]
05-29
2005
[Talk]
[Talk]
Performance Degradataion in the Presence of Subnormal Floating-Point Values [OSIHPA 2005]
05-28
2005
[Talk]
[Talk]
Parallelization Of The Spacetime Discontinuous Galerkin Method Using The Charm++ ParFUM Framework [USNCCM 2005]
05-27
2005
[Talk]
[Talk]
Adaptive MPI: Intelligent Runtime Strategies and Performance Prediction via Simulation [Future Technologies Colloquium Series 2005]
05-26
2005
[Poster]
[Poster]
Speeding Up Parallel Simulation with Automatic Load Balancing [PPL Poster 2005]
05-25
2005
[Poster]
[Poster]
Parallel VHDL Simulation [PPL Poster 2005]
04-26
2004
[Talk]
[Talk]
An Orchestration Language for Parallel Objects [LCR 2004]
04-25
2004
[Talk]
[Talk]
Scaling Collective Multicast on Fat-tree Networks [ICPADS 2004]
04-24
2004
[Talk]
[Talk]
Opportunity and Challanges of Modern Communication Architectures: Case Study with QsNet [CAC Workshop at IPDPS 2004]
04-23
2004
[Talk]
[Talk]
FTC-Charm++: An In-Memory Checkpoint-Based Fault Tolerant Runtime for Charm++ and MPI [Cluster 2004]
04-22
2004
[Talk]
[Talk]
BigSim: A Parallel Simulator for Performance Prediction of Extremely Large Parallel Machines [IPDPS 2004]
04-21
2004
[Talk]
[Talk]
A Fault Tolerant Protocol for Massively Parallel Machines [IPDPS 2004]
04-20
2004
[Talk]
[Talk]
Using Multiphase Shared Arrays [LCPC 2004]
04-19
2004
[Poster]
[Poster]
Salsa: a Parallel, Interactive, Particle-Based Analysis Tool [SC 2004]
03-29
2003
[Talk]
[Talk]
Survey on Mesh formats for Scientific Computing [Concurrency and Computation: Practice and Experience 2003]
03-28
2003
[Talk]
[Talk]
Introduction to Performance Tuning [No Conference 2003]
03-27
2003
[Talk]
[Talk]
Charm++/AMPI Tutorial [LACSI 2003]
03-26
2003
[Talk]
[Talk]
Faucets Tutorial [LACSI 2003]
03-25
2003
[Talk]
[Talk]
Quantum Chemistry Presentation at Lyon [No Conference 2003]
03-24
2003
[Talk]
[Talk]
Adaptive MPI [LCPC 2003]
03-23
2003
[Talk]
[Talk]
Parallel Spacetime Discontinuous Galerkin Methods [USNCCM 2003]
03-22
2003
[Talk]
[Talk]
Parallelization of CPAIMD using Charm++ [No Conference 2003]
03-21
2003
[Talk]
[Talk]
A Framework for Collective Personalized Communication [IPDPS 2003]
03-20
2010
[Talk]
[Talk]
Bluegene Timestamp Correction [No Conference 2010]
02-17
2002
[Talk]
[Talk]
Adaptive MPI [No Conference 2002]
02-16
2002
[Talk]
[Talk]
Molecular Dynamics on Thousands of Processors [SC 2002]
02-15
2002
[Talk]
[Talk]
Runtime Optimizations via Processor Virtualization [LACSI 2002]
02-14
2002
[Talk]
[Talk]
Charm++ Internals [No Conference 2002]
02-13
2002
[Talk]
[Talk]
Charm++ Internals - Introduction to Charm++ Machine Layer [No Conference 2002]
02-12
2002
[Talk]
[Talk]
Charm++ Overview and Simple Examples [No Conference 2002]
02-11
2002
[Talk]
[Talk]
Faucets: Efficient Utilization of Multiple Clusters [Charm++ Workshop 2002]
01-14
2001
[Talk]
[Talk]
Charm++ Arrays, Parameter Marshalling, and Load Balancing [JGI 2001]
01-13
2001
[Talk]
[Talk]
Faucets [No Conference 2001]
01-12
2001
[Talk]
[Talk]
Faucets Queueing Systems [No Conference 2001]
01-11
2001
[Talk]
[Talk]
BlueGene Emulator [IPDPS 2001]
01-10
2001
[Talk]
[Talk]
NAMD [No Conference 2001]
01-09
2001
[Talk]
[Talk]
Adaptive Mesh Refinement (AMR) [No Conference 2001]
01-08
2001
[Talk]
[Talk]
Parallel Object-oriented Simulation Environment (POSE) [No Conference 2001]
01-07
2001
[Talk]
[Talk]
Component Frameworks for Parallel Applications [No Conference 2001]
98-11
1998
[Talk]
[Talk]
Load Balancing in Parallel Molecular Dynamics [International Symposium on Solving Irregularly Structured Problems in Parallel 1998]
96-23
1996
[Talk]
[Talk]
Charm++: A Portable Concurrent Object Oriented System Based on C++ [OOPSLA 1996]
96-22
1996
[Talk]
[Talk]
CONVERSE: an Interoperable Framework for Parallel Programming [IPPS 1996]
96-21
1996
[Talk]
[Talk]
Efficient Parallel Graph Coloring with Prioritization [PSLS 1996]
96-20
1996
[Talk]
[Talk]
Towards Automatic Performance Analysis of Parallel Programs [ICPP 1996]
96-19
1996
[Talk]
[Talk]
Automatic Parallel Runtime Optimizations using Post-Mortem Analysis [ICS 1996]
96-18
2010
[Talk]
[Talk]
Charm++: What Have We Learned? [No Conference 2010]
96-17
1996
[Talk]
[Talk]
Threads for Interoperable Parallel Programming [LCPC 1996]
96-16
1996
[Talk]
[Talk]
A Parallel Array Abstraction for Data-Driven Objects [POOMA 1996]
95-19
1995
[Talk]
[Talk]
Efficient Implementation of High Performance Fortran via Adaptive Scheduling - An Overview [IWPP 1995]
95-18
1995
[Talk]
[Talk]
Modularity, Reuse and Efficiency with Message-Driven Libraries [PPSC 1995]
95-17
1995
[Talk]
[Talk]
Agents: An Undistorted Representation of Problem Structure [LCPC 1995]
94-06
1994
[Talk]
[Talk]
Dagger: Combining Benefits of Synchronous and Asynchronous Communication Styles [IPPS 1994]
91-10
1991
[Talk]
[Talk]
Supporting Machine Independent Parallel Programming on Diverse Parallel Architectures [ICPP 1991]