









Parallel Languages/Paradigms:
Charm++
Parallel Programming with Migratable Objects
Relevant links: exascale relevance, the manual, mini-apps, downloads, charmplusplus.org
Charm++ is a machine independent parallel programming system. Programs written using this system will run unchanged on MIMD machines with or without a shared memory. It provides high-level mechanisms and strategies to facilitate the task of developing even highly complex parallel applications.
Charm++ programs are written in C++ with a few library calls and an interface description language for publishing Charm++ objects. Charm++ supports multiple inheritance, late bindings, and polymorphism.
Platforms: The system currently runs on IBM's Blue Gene/Q and OpenPOWER systems, Cray XE6, XK7, and XC40 systems, Infiniband and Omni-Path clusters, clusters of UNIX workstations and even single-processor UNIX, Mac, and Windows machines. It also contains support for running on accelerators such as Xeon Phis and GPGPUs.
The design of the system is based on the following tenets:
- Efficient Portability: Portability is an essential catalyst for the development of reusable parallel software. Charm++ programs run unchanged on MIMD machines with or without a shared memory. The programming model induces better data locality, allowing it to support machine independence without losing efficiency.
- Latency Tolerance: Latency of communication - the idea that remote data will take longer to access - is a significant issue common across most MIMD platforms. Message-driven execution, supported in Charm++, is a very useful mechanism for tolerating or hiding this latency. In message driven execution (which is distinct from just message-passing), a processor is allocated to a process only when a message for the process is received. This means when a process blocks, waiting for a message, another process may execute on the processor. It also means that a single process may block for any number of distinct messages, and will be awakened when any of these messages arrive. Thus, it forms an effective way of scheduling a processor in the presence of potentially large latencies.
- Dynamic Load Balancing: Dynamic creation and migration of work is necessary in many applications. Charm++ supports this by providing dynamic (as well as static) load balancing strategies.
- Reuse and Modularity: It should be possible to develop parallel software by reusing existing parallel software. Charm++ supports this with a well-developed ``module'' construct and associated mechanisms. These mechanisms allow for compositionality of modules without sacrificing the latency-tolerance. With them, two modules, each spread over hundreds of processors, may exchange data in a distributed fashion.
The Programming Model: Programs consist of potentially medium-grained processes (called chares), a special type of replicated process, and collections of chares. These processes interact with each other via messages. There may be thousands of medium-grained processes on each processor, or just a few, depending on the application. The ``replicated processes'' can also be used for implementing novel information sharing abstractions, distributed data structures, and intermodule interfaces. The system can be considered a concurrent object-oriented system with a clear separation between sequential and parallel objects. As shown in this figure, the objects are mapped by the runtime system to appropriate processors to balance the load.
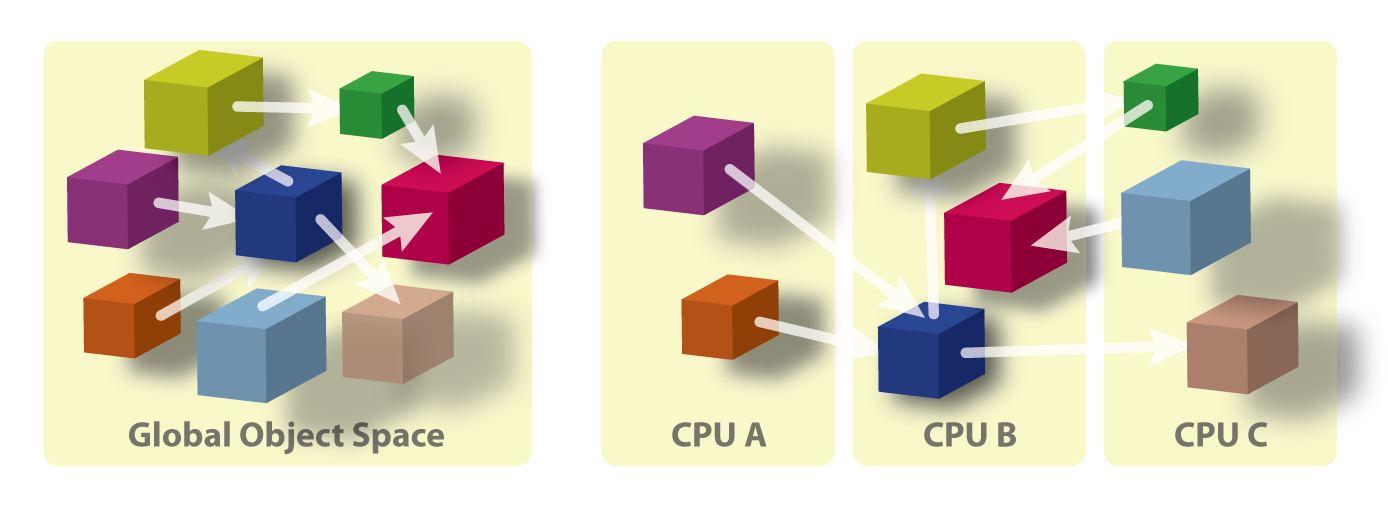
Reusable Libraries: The modularity-related features make the system very attractive for building library modules that are highly reusable because they can be used in a variety of data-distributions. We have just begun the process of building such libraries, and have a small collection of library modules. However, we expect such libraries, contributed by us and other users, to be one of the most significant aspects of the system.
Regular and Irregular Computations: For regular computations, the system is useful because it provides portability, static load balancing, and latency tolerance via message driven execution, and facilitates construction and flexible reuse of libraries. The system is unique for the extensive support it provides for highly irregular computations. This includes management of many medium-grained processes, support for prioritization, dynamic load balancing strategies, handling of dynamic data-structures such as lists and graphs, etc.
People
Papers/Talks
22-05
2022
[Paper]
[Paper]
Improving Scalability with GPU-Aware Asynchronous Tasks [HIPS 2022]
22-02
2021
[Paper]
[Paper]
Accelerating Messages by Avoiding Copies in an Asynchronous Task-based Programming Model [ESPM2 2021]
22-01
2021
[Paper]
[Paper]
Enabling Support for Zero Copy Semantics in an Asynchronous Task-Based Programming Model [Asynchronous Many-Task Systems for Exascale Workshop 2021]
20-03
2020
[Paper]
[Paper]
Scalable molecular dynamics on CPU and GPU architectures with NAMD [J. Chem. Phys. 2020]
18-02
2018
[Paper]
[Paper]
Multi-level Load Balancing with an Integrated Runtime Approach [CCGrid 2018]
17-08
2017
[Paper]
[Paper]
Integrating OpenMP into the Charm++ Programming Model [ESPM2 2017]
16-20
2016
[PhD Thesis]
[PhD Thesis]
Mitigation of failures in high performance computing via runtime techniques [Thesis 2016]
16-19
2016
[Paper]
[Paper]
Handling Transient and Persistent Imbalance Together in Distributed and Shared Memory [PPL Technical Report 2016]
16-14
2016
[Paper]
[Paper]
Runtime Coordinated Heterogeneous Tasks in Charm++ [ESPM2 2016]
16-05
2016
[Paper]
[Paper]
OpenAtom: Scalable Ab-Initio Molecular Dynamics with Diverse Capability [ISC 2016]
14-31
2014
[Talk]
[Talk]
Scalable Replay with Partial-Order Dependencies for Message-Logging Fault Tolerance [Cluster 2014]
14-21
2014
[Paper]
[Paper]
Scalable Replay with Partial-Order Dependencies for Message-Logging Fault Tolerance [Cluster 2014]
14-19
2014
[Paper]
[Paper]
Position Paper: Power-aware and Temperature Restrain Modeling for Maximizing Performance and Reliability [MODSIM 2014]
14-12
2014
[Paper]
[Paper]
PICS: A Performance-Analysis-Based Introspective Control System to Steer Parallel Applications [ROSS 2014]
13-46
2013
[Paper]
[Paper]
Parallel Science and Engineering Applications: The Charm++ Approach: Chapter 1: The Charm++ Programming Model [Book 2013]
13-45
2013
[Paper]
[Paper]
Parallel Science and Engineering Applications: The Charm++ Approach: Chapter 2: Designing Charm++ Programs [Book 2013]
13-44
2013
[Paper]
[Paper]
Parallel Science and Engineering Applications: The Charm++ Approach: Chapter 3: Tools for Debugging and Performance Analysis [Book 2013]
13-43
2013
[Paper]
[Paper]
Parallel Science and Engineering Applications: The Charm++ Approach: Chapter 4: Scalable Molecular Dynamics with NAMD [Book 2013]
13-42
2013
[Paper]
[Paper]
Parallel Science and Engineering Applications: The Charm++ Approach: Chapter 5: OpenAtom: Ab-initio Molecular Dynamics for Petascale Platforms [Book 2013]
13-41
2013
[Paper]
[Paper]
Parallel Science and Engineering Applications: The Charm++ Approach: Chapter 6: N-body Simulations with ChaNGa [Book 2013]
13-40
2013
[Paper]
[Paper]
Parallel Science and Engineering Applications: The Charm++ Approach: Chapter 7: Remote Visualization of Cosmological Data using Salsa [Book 2013]
13-39
2013
[Paper]
[Paper]
Parallel Science and Engineering Applications: The Charm++ Approach: Chapter 8: Improving Scalability of BRAMS: a Regional Weather Forecast Model [Book 2013]
13-38
2013
[Paper]
[Paper]
Parallel Science and Engineering Applications: The Charm++ Approach: Chapter 9: Crack Propagation Analysis with Automatic Load Balancing [Book 2013]
13-37
2013
[Paper]
[Paper]
Parallel Science and Engineering Applications: The Charm++ Approach: Chapter 10: Contagion Diffusion with EpiSimdemics [Book 2013]
13-36
2012
[Paper]
[Paper]
Controlling Concurrency and Expressing Synchronization in Charm++ Programs [Concurrent Objects and Beyond 2012]
13-16
2013
[Paper]
[Paper]
Parallel Science and Engineering Applications: The Charm++ Approach [Book 2013]
13-03
2013
[Poster]
[Poster]
Charm++: Migratable Objects + Active Messages + Adaptive Runtime = Productivity + Performance [PSAAP Site-visit 2013]
{kind=link}
12-09
2012
[Talk]
[Talk]
Composable and Modular Exascale Programming Models with Intelligent Runtime Systems [Sandia Talk 2012]
11-56
2011
[Talk]
[Talk]
Charm++ Tutorial [ICS 2011]
11-48
2011
[Talk]
[Talk]
Charm++ for Productivity and Performance: A Submission to the 2011 HPC Class II Challenge [SC 2011]
11-41
2011
[Paper]
[Paper]
Using Shared Arrays in Message-Driven Parallel Programs [ParCo 2011]
11-27
2011
[Paper]
[Paper]
Optimizations for Message Driven Applications on Multicore Architectures [HiPC 2011]
10-13
2010
[Paper]
[Paper]
Optimizing a Parallel Runtime System for Multicore Clusters: A Case Study [TeraGrid 2010]
10-06
2009
[Paper]
[Paper]
Charm++ and AMPI: Adaptive Runtime Strategies via Migratable Objects [Advanced Computational Infrastructures for Parallel and Distributed Applications 2009]
08-09
2008
[Paper]
[Paper]
Some Essential Techniques for Developing Efficient Petascale Applications [SciDAC 2008]
07-04
2007
[Paper]
[Paper]
Programming Petascale Applications with Charm++ and AMPI [Petascale Computing: Algorithms and Applications 2007]
05-06
2005
[PhD Thesis]
[PhD Thesis]
Achieving High Performance on Extremely Large Parallel Machines: Performance Prediction and Load Balancing [Thesis 2005]
04-16
2004
[Paper]
[Paper]
Performance and Modularity Benefits of Message-Driven Execution [Journal of Parallel and Distributed Computing 2004]
03-17
2003
[MS Thesis]
[MS Thesis]
An Efficient Implementation of Charm++ on Virtual Machine Interface [Thesis 2003]
96-11
1996
[Paper]
[Paper]
Charm++: Parallel Programming with Message-Driven Objects [Book Chapter 1996]
96-09
1995
[Paper]
[Paper]
Threads for Interoperable Parallel Programming [LCPC 1995]
95-03
1995
[Paper]
[Paper]
The Charm Parallel Programming Language and System:Part II - The Runtime System [PPL Technical Report 1995]
95-02
1994
[Paper]
[Paper]
The Charm Parallel Programming Language and System:Part I --- Description of Language Features [PPL Technical Report 1994]
93-02
1993
[Paper]
[Paper]
CHARM++ : A Portable Concurrent Object Oriented System Based On C++ [OOPSLA 1993]
90-10
1990
[PhD Thesis]
[PhD Thesis]
Machine Independent Parallel Execution of Speculative Computations [Thesis 1990]
90-08
1990
[Paper]
[Paper]
Chare Kernel - A Runtime Support System for Parallel Computations [Journal of Parallel and Distributed Computing 1990]
90-03
1990
[Paper]
[Paper]
The Chare Kernel Parallel Programming Language and System [ICPP 1990]