









Runtime Systems and Tools:
Fault Tolerance Support
As both modern supercomputers and new generation scientific computing applications grow in size and complexity, the probability of system failure rises commensurately. Making parallel computing fault tolerant has become an increasingly important issue.
At PPL, we have research (and resultant software) on multiple schemes that support fault tolerance:(1) automated traditional checkpoint with restart on a different number of processors (2) an in-remote-memory (or in-local-disk) double checkpointing scheme for online fault recovery (3) an ongoing research project that avoids sending all processors back to their checkpoints, and speeds up restart (4) a proactive fault avoidance scheme that evacuates a processor while letting the computation continue.
On-disk checkpoint/restart is the simplest approach. It requires synchronization in the system. In AMPI, this is invoked by a collective call. All the data is saved as disk files on a file server. When a processor crashes, the application is killed and then restarted from its checkpoint. This approach allows the scheduler more flexibility, since a job can be restarted on a different number of processors.
Double checkpoint-based fault tolerance for Charm++ and AMPI.
The above traditional disk-based method of dealing with faults is to checkpoint the state of the entire application periodically to reliable storage and restart from the recent checkpoint. The recovery of the application from faults involves (often manually) restarting applications on all processors and having it read the data from disks on all processors. The restart can therefore take minutes after it has been initiated. Traditional strategies often require that the failed processor can be replaced so that the number of processors at checkpoint-time and recovery-time are the same. Double in-memory checkpoint/restart is a scheme for fast and scalable in-memory checkpoint and restart. The scheme
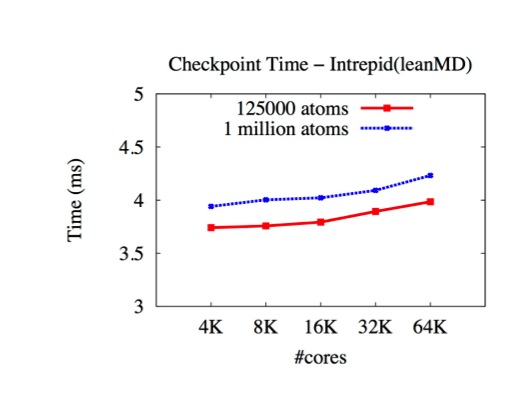
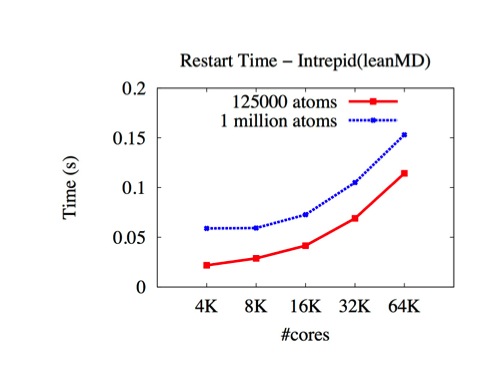
For applications (wave2D and ChaNGa) uses asynchronous checkpointing, the checkpoint time is further reduced as shown below (on Trestles).
FTL-Charm++:is a sender based pessimistic fault tolerant protocol for Charm++ and AMPI. The sender saves a copy of the message in its memory while sending a message to an object on another processor. It sends a ticket request to the receiver, which replies with a ticket. A ticket is the sequence in which the receiver will process this message. The sender saves the ticket in its memory and sends the message to the receiver. For messages sent to an object on the same processor, the ticket number is fetched through a function call and along with the sender and receiver's id is saved on a buddy processor. This allows message logging to work along with virtualization. While restarting after a crash, this protocol can spread the objects on the restarted processor among other processors. This provides for much faster restarts compared to other message logging protocols where all the work of the restarted processor is done on one processor. Checkpoint based protocols, which rollback all processors to their previous checkpoint when one processor crashes, obviously cannot redistribute work from the restarted processor as all processors are busy. So our protocol is unique in allowing restarts much faster than the time between the crash and the previous checkpoint. Work is going on to combine the message logging protocol with migration of objects to allow us to do dynamic runtime load balancing.
Proactive Fault Tolerance: is a scheme for reacting to fault warnings for Charm++ and AMPI. Modern hardware and fault prediction schemes can predict many faults with a good degree of accuracy. We developed a scheme for reacting to such faults. When a node is warned that it might crash, the charm++ objects on it are migrated away. The runtime system is also changed so that message delivery can continue seamlessly even if the warned node crashes. Reduction trees are also modified to remove the warned node from the tree so that its crash does not cause the tree to become disconnected. A node in the tree is replaced by one of its children. If the tree becomes too unbalanced, the whole reduction tree can be recreated from scratch. The proactive fault tolerance protocol does not require any extra nodes, it continues working on the remaining ones. It can deal with multiple simultaneous warnings, which is useful for real life cases where all the nodes in a rack are about to go down.
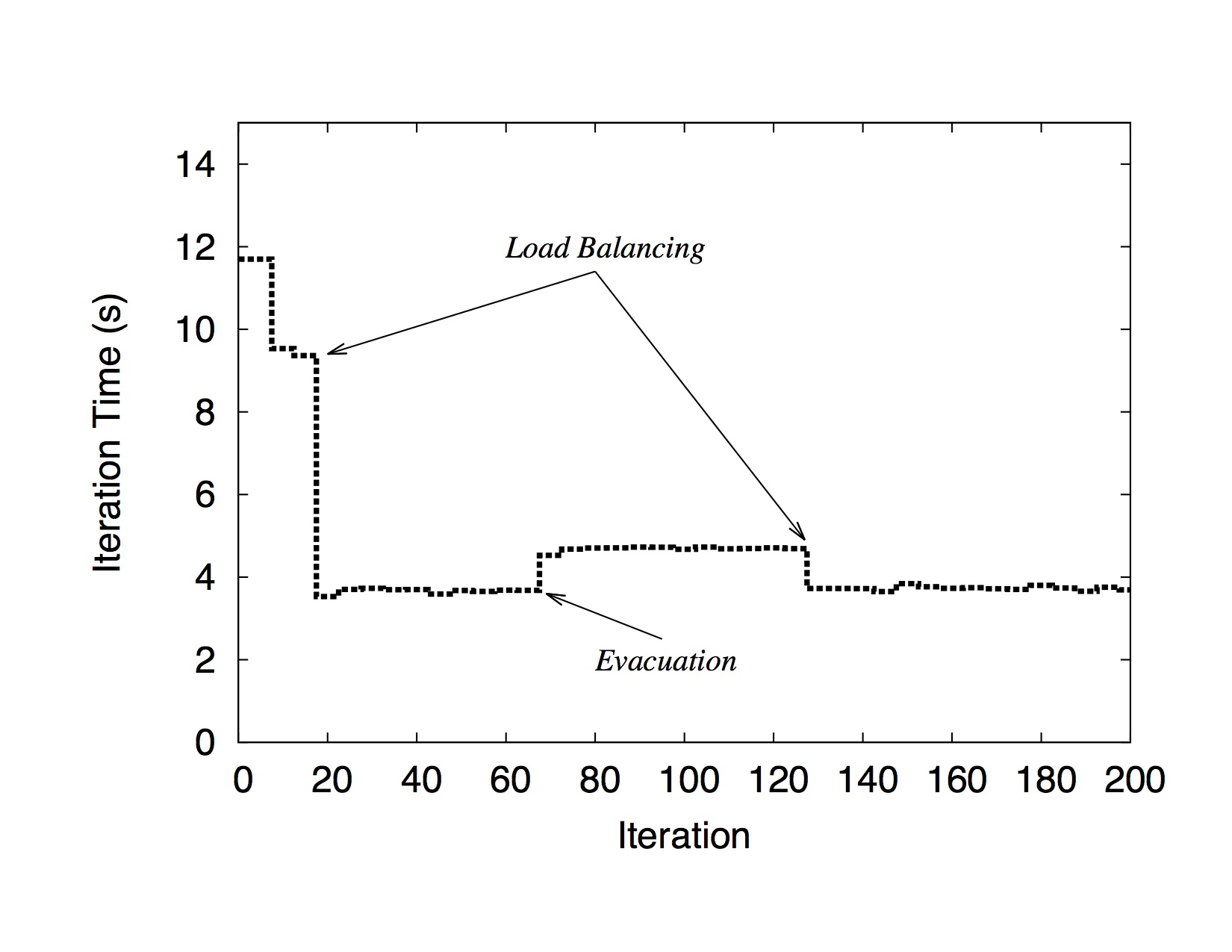
Below we show a run of NPB BT-MZ on 256 cores of Ranger with proactive fault tolerance support. The first load balancing at iteration 20 solves the initial load imbalancing of the application. At iteration 60, one core receives the signal of failure and objects on it migrate to other cores which creates a load imbalancing in the system. The problem is solved by applying load balancing once more.
Comparisons of these schemes:
At PPL, we have research (and resultant software) on multiple schemes that support fault tolerance:(1) automated traditional checkpoint with restart on a different number of processors (2) an in-remote-memory (or in-local-disk) double checkpointing scheme for online fault recovery (3) an ongoing research project that avoids sending all processors back to their checkpoints, and speeds up restart (4) a proactive fault avoidance scheme that evacuates a processor while letting the computation continue.
On-disk checkpoint/restart is the simplest approach. It requires synchronization in the system. In AMPI, this is invoked by a collective call. All the data is saved as disk files on a file server. When a processor crashes, the application is killed and then restarted from its checkpoint. This approach allows the scheduler more flexibility, since a job can be restarted on a different number of processors.
Double checkpoint-based fault tolerance for Charm++ and AMPI.
The above traditional disk-based method of dealing with faults is to checkpoint the state of the entire application periodically to reliable storage and restart from the recent checkpoint. The recovery of the application from faults involves (often manually) restarting applications on all processors and having it read the data from disks on all processors. The restart can therefore take minutes after it has been initiated. Traditional strategies often require that the failed processor can be replaced so that the number of processors at checkpoint-time and recovery-time are the same. Double in-memory checkpoint/restart is a scheme for fast and scalable in-memory checkpoint and restart. The scheme
- does not require any individual component to be fault-free because checkpoint data is stored in two copies on two different locations. (although not infalliable)
- provides fast and efficient checkpoint and restart using memory for checkpointing. It can take advantage of high performance network to speedup checkpointing process.
- at restart, it provides fault tolerance support for both cases with or without backup processors. If there are no backup processors, the program can continue to run on the remaining processors without performance penalty due to load imbalance.
- the memory-based method is useful for applications where the memory footprint is small at the checkpoint state, while a variation of this scheme --- in-disk checkpoint/restart can be applied to applications with large memory footprint. It uses local scratch disk for storing checkpoints, which is much more efficient than using centralized reliable file server.
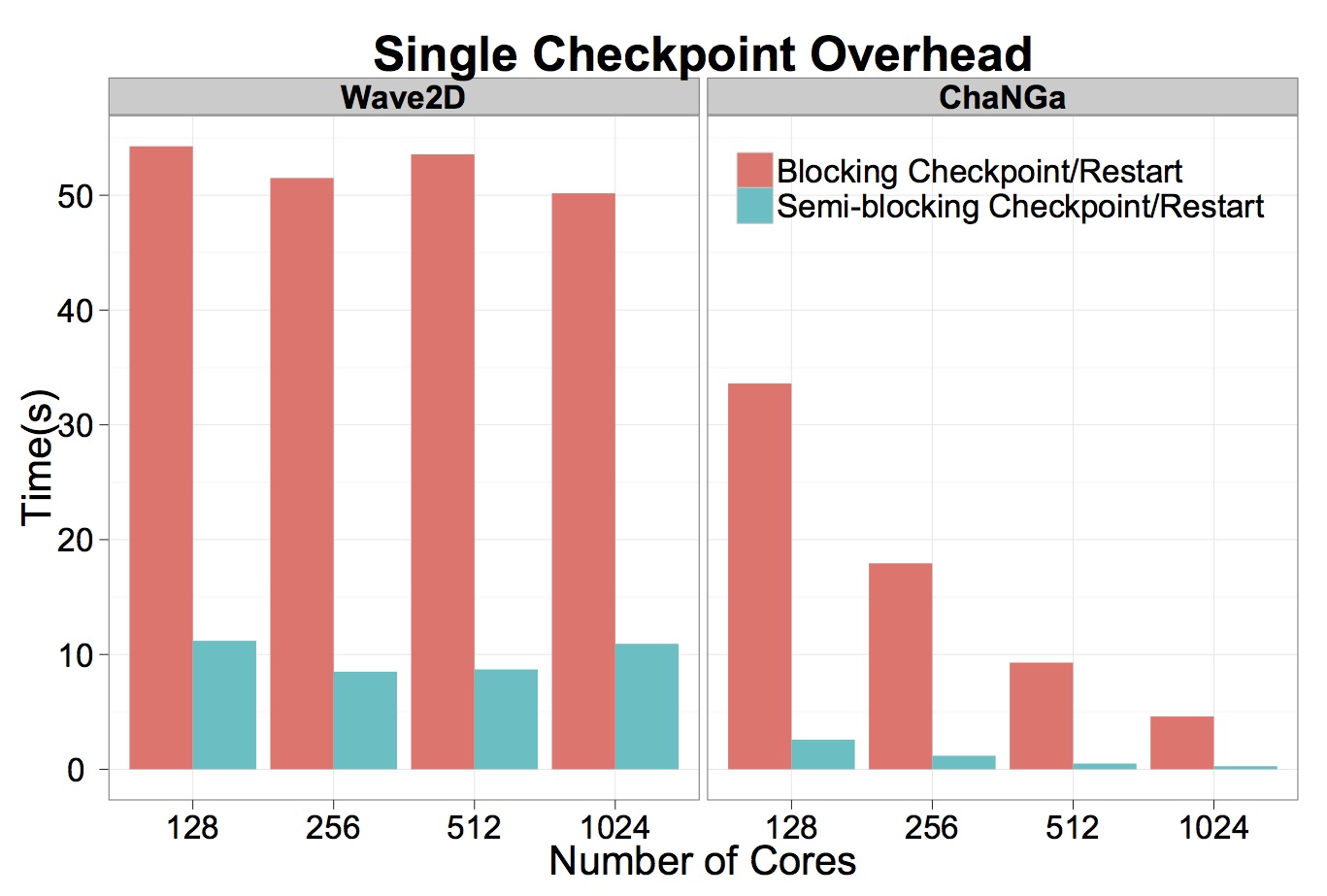
- provides asynchronous checkpointing support for applications have moderate checkpoint size to relieve the network pressure. There are two phases in the support. In the first phase, after reaching a global synchronization point, each node will store its checkpoint in the main memory. After every node safely stores the newest copy of the checkpoint, they will resume to the normal execution. Then, the Charm++ runtime system will take the responsibility to send the checkpoints of each node to another node as a double copy at the appropriate time: when the applications are busy computing and leave the network free.
For applications (wave2D and ChaNGa) uses asynchronous checkpointing, the checkpoint time is further reduced as shown below (on Trestles).
FTL-Charm++:is a sender based pessimistic fault tolerant protocol for Charm++ and AMPI. The sender saves a copy of the message in its memory while sending a message to an object on another processor. It sends a ticket request to the receiver, which replies with a ticket. A ticket is the sequence in which the receiver will process this message. The sender saves the ticket in its memory and sends the message to the receiver. For messages sent to an object on the same processor, the ticket number is fetched through a function call and along with the sender and receiver's id is saved on a buddy processor. This allows message logging to work along with virtualization. While restarting after a crash, this protocol can spread the objects on the restarted processor among other processors. This provides for much faster restarts compared to other message logging protocols where all the work of the restarted processor is done on one processor. Checkpoint based protocols, which rollback all processors to their previous checkpoint when one processor crashes, obviously cannot redistribute work from the restarted processor as all processors are busy. So our protocol is unique in allowing restarts much faster than the time between the crash and the previous checkpoint. Work is going on to combine the message logging protocol with migration of objects to allow us to do dynamic runtime load balancing.
Proactive Fault Tolerance: is a scheme for reacting to fault warnings for Charm++ and AMPI. Modern hardware and fault prediction schemes can predict many faults with a good degree of accuracy. We developed a scheme for reacting to such faults. When a node is warned that it might crash, the charm++ objects on it are migrated away. The runtime system is also changed so that message delivery can continue seamlessly even if the warned node crashes. Reduction trees are also modified to remove the warned node from the tree so that its crash does not cause the tree to become disconnected. A node in the tree is replaced by one of its children. If the tree becomes too unbalanced, the whole reduction tree can be recreated from scratch. The proactive fault tolerance protocol does not require any extra nodes, it continues working on the remaining ones. It can deal with multiple simultaneous warnings, which is useful for real life cases where all the nodes in a rack are about to go down.
Below we show a run of NPB BT-MZ on 256 cores of Ranger with proactive fault tolerance support. The first load balancing at iteration 20 solves the initial load imbalancing of the application. At iteration 60, one core receives the signal of failure and objects on it migrate to other cores which creates a load imbalancing in the system. The problem is solved by applying load balancing once more.
Comparisons of these schemes:
People
Papers/Talks
16-20
2016
[PhD Thesis]
[PhD Thesis]
Mitigation of failures in high performance computing via runtime techniques [Thesis 2016]
16-15
2016
[Paper]
[Paper]
FlipBack: Automatic Targeted Protection Against Silent Data Corruption [SC 2016]
15-16
2015
[Paper]
[Paper]
A Fault-Tolerance Protocol for Parallel Applications with Communication Imbalance [SBAC-PAD 2015]
14-31
2014
[Talk]
[Talk]
Scalable Replay with Partial-Order Dependencies for Message-Logging Fault Tolerance [Cluster 2014]
14-21
2014
[Paper]
[Paper]
Scalable Replay with Partial-Order Dependencies for Message-Logging Fault Tolerance [Cluster 2014]
14-20
2014
[Paper]
[Paper]
Using Migratable Objects to Enhance Fault Tolerance Schemes in Supercomputers [IEEE Transactions on Parallel and Distributed Systems 2014]
14-02
2014
[Paper]
[Paper]
Energy Profile of Rollback-Recovery Strategies in High Performance Computing [ParCo 2014]
13-50
2013
[Talk]
[Talk]
A ‘Cool’ Way of Improving the Reliability of HPC Machines [SC 2013]
13-25
2013
[Paper]
[Paper]
A ‘Cool’ Way of Improving the Reliability of HPC Machines [SC 2013]
13-24
2013
[Paper]
[Paper]
ACR: Automatic Checkpoint/Restart for Soft and Hard Error Protection [SC 2013]
13-17
2013
[PhD Thesis]
[PhD Thesis]
Scalable Message-Logging Techniques for Effective Fault Tolerance in HPC Applications [Thesis 2013]
13-06
2013
[Talk]
[Talk]
Adoption Protocols for Fanout-Optimal Fault-Tolerant Termination Detection [PPoPP 2013]
12-46
2013
[Paper]
[Paper]
Adoption Protocols for Fanout-Optimal Fault-Tolerant Termination Detection [PPoPP 2013]
12-43
2012
[Talk]
[Talk]
Assessing Energy Efficiency of Fault Tolerance Protocols for HPC Systems [SBAC-PAD 2012]
12-37
2012
[Paper]
[Paper]
Assessing Energy Efficiency of Fault Tolerance Protocols for HPC Systems [SBAC-PAD 2012]
12-32
2012
[Paper]
[Paper]
Hiding Checkpoint Overhead in HPC Applications with a Semi-Blocking Algorithm [Cluster 2012]
12-30
2012
[Talk]
[Talk]
A Message-Logging Protocol for Multicore Systems [FTXS 2012]
12-15
2012
[MS Thesis]
[MS Thesis]
A Semi-Blocking Checkpoint Protocol to Minimize Checkpoint Overhead [Thesis 2012]
12-14
2012
[Paper]
[Paper]
A Message-Logging Protocol for Multicore Systems [FTXS 2012]
12-12
2012
[Paper]
[Paper]
A Scalable Double In-memory Checkpoint and Restart Scheme towards Exascale [FTXS 2012]
12-09
2012
[Talk]
[Talk]
Composable and Modular Exascale Programming Models with Intelligent Runtime Systems [Sandia Talk 2012]
12-04
2012
[Paper]
[Paper]
A Scalable Double In-memory Checkpoint and Restart Scheme towards Exascale [PPL Technical Report 2012]
11-38
2011
[Talk]
[Talk]
Dynamic Load Balance for Optimized Message Logging in Fault Tolerant HPC Applications [Cluster 2011]
11-30
2011
[Paper]
[Paper]
Design and Analysis of a Message Logging Protocol for Fault Tolerant Multicore Systems [PPL Technical Report 2011]
11-26
2011
[Paper]
[Paper]
Dynamic Load Balance for Optimized Message Logging in Fault Tolerant HPC Applications [Cluster 2011]
11-04
2011
[Paper]
[Paper]
Evaluation of Simple Causal Message Logging for Large-Scale Fault Tolerant HPC Systems [DPDNS 2011]
10-02
2010
[Paper]
[Paper]
Team-based Message Logging: Preliminary Results [Resilience 2010]
08-16
2008
[PhD Thesis]
[PhD Thesis]
A Fault Tolerance Protocol for Fast Recovery [Thesis 2008]
06-12
2007
[Paper]
[Paper]
A Fault Tolerance Protocol with Fast Fault Recovery [IPDPS 2007]
06-11
2006
[Paper]
[Paper]
Proactive Fault Tolerance in MPI Applications via Task Migration [HiPC 2006]
06-04
2006
[Paper]
[Paper]
HPC-Colony: Services and Interfaces for Very Large Systems [OSR Special Issue on HEC OS/Runtimes 2006]
06-03
2006
[Paper]
[Paper]
Performance Evaluation of Automatic Checkpoint-based Fault Tolerance for AMPI and Charm++ [Operating and Runtime Systems for High-end Computing Systems 2006]
04-14
2005
[Paper]
[Paper]
Proactive Fault Tolerance in Large Systems [HPCRI 2005]
04-07
2004
[MS Thesis]
[MS Thesis]
System Support for Checkpoint/Restart of Charm++ and AMPI Applications [Thesis 2004]
04-06
2004
[Paper]
[Paper]
FTC-Charm++: An In-Memory Checkpoint-Based Fault Tolerant Runtime for Charm++ and MPI [Cluster 2004]
04-03
2004
[Paper]
[Paper]
A Fault Tolerant Protocol for Massively Parallel Systems [FTPDS 2004]