










I am a research staff member at the lab, where my work focuses on evolving and scaling the core components of the Charm++ runtime system as well as helping Charm++ applications parallelize and scale their algorithms.
I've worked on several aspects of the programming framework and adaptive runtime system, and have a good understanding of how to build and scale runtime components for managed, distributed parallelism. I've also worked on scaling parallel applications here at PPL; and at the Computational Simulation Lab and the Section on Statistical Genetics, both at the University of Alabama at Birmingham.
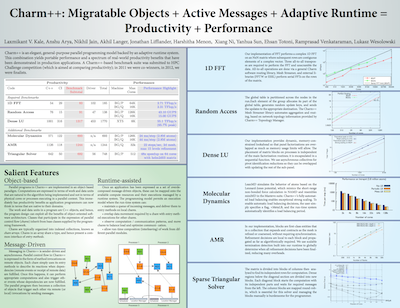
My interests lie at the confluence of scalable algorithms for application domains, programming models for expressing these parallel algorithms, runtime systems for managing the parallelism, and extracting performance at extreme scale. There are several research questions in each of these, and I hope to find and express some of the answers in a useful form by building massively parallel software systems.
I strongly believe that managed parallelism is key to performance. Parallel programs should just express domain logic with annotations that permit other software components to manage execution and extract performance. This has already been demonstrated by several successful parallel programming frameworks in industry and research. Such managed parallelism becomes possible when algorithms express only the dependencies and minimum requirements of when a computation can execute, instead of dictating when a computation should execute. This approach, coupled with the expression of more parallelism than available hardware concurrency (overdecomposition), permits high performance.
The general-purpose, Charm++ programming model embodies many of these principles: overdecomposed, migratable objects, driven by asynchronous methods, and orchestrated by a runtime system that observes and adapts for better performance.
- Quantum chemistry
- Stochastic optimization for resource allocation
- Parallel, dense, linear algebra
- Bayesian methods for gene-trait mapping
- Haplotype reconstruction from genetic data
- Atomistic, rarefied gas dynamics
- Continuum fluid dynamics
- Equilibrium and finite-rate combustion chemistry
- Hybrid continuum-atomistic fluid flows
[Thesis]
[Paper]
[Talk]
[Paper]
[Paper]
[Paper]
[Paper]
[Paper]
[Paper]
[Paper]
[Paper]
[Paper]
[Paper]
[Paper]
[Paper]
[Paper]
[Paper]
[Talk]
[Talk]
[Poster]
{kind=link}
[Talk]
[Talk]
[Talk]
[Poster]