









Scientific Applications:
NChilada
(archived page)
It Involves various algorithms, with the basic parallel data structure being particles organized into trees (OctTree, ORB, or Space Filling Curve). A common tree abstract is being created to simplify the conversion between tree models, and to provide common interface for various operations on the particles stored in the tree structures. As an example, the user can demand for the neighbors within a given distance for one or all of the particles, and apply a certain calculation on the neighbors.
The algorithm being studied for the force computation uses the typical Barnes-Hut O(nlogn) structure to reduce the amount of computation performed. In order to compute the pair interaction between particles and nodes on different processors, the parts of the tree needed for the computation of a particle are imported from the processor where that particle belongs to. This implies both an explosion of the memory used for large datasets, and the need to structure the import so that the external nodes are transferred only once and used by all the particles which need them. For this reason, a CacheManager has been built, with the functionality of a software cache.
The main structure of the program involves a chare array (called TreePiece) to hold the particle data and the associated tree structures, and a group (called CacheManager) to hold the imported structures. The main control flow of the force computation is expressed in the figure here below.
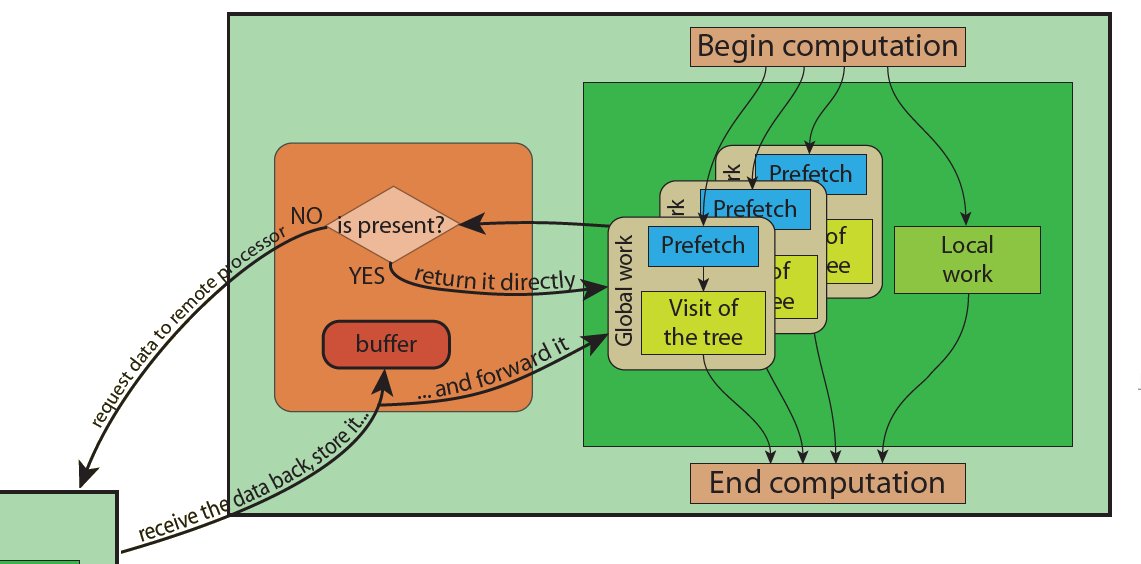 Processor control flow
Processor control flow
The picture represents the workflow inside a single processor. After the computation is started globally, each TreePiece (green box) receives messages to perform its part. The TreePiece splits the total work into local work, which includes interaction with its own portion of the tree, and global work, which includes interaction with the rest of the system. The global work is composed of two stages: prefetching of the needed data, and visit of the tree. During the global work, the TreePiece requests the CacheManager (orange box) for data not locally present. If the data is already buffered, it is immediately returned, otherwise it is requested to another processor. When the data comes back, it is buffered and forwarded to the requesting TreePiece. In order to mask the latency occurring while fetching remote data, the global work is divided into chunks, and the computation is executed in a pipelined fashion. Moreover, the local work is used as an additional source of computation to mask the latency.
After having a basic version of ChaNGa in place, we studied its performance and added a number of optimizations to the code. Some of these optimizations were designed to exploit Charm++ aspects that enable high performance, whereas others were aimed at specific characteristics of particle codes. The current ChaNGa code (with all the optimizations) scales pretty well on large parallel machines like BlueGene/L, IBM HPCx, NCSA Tungsten with real cosmological datasets.
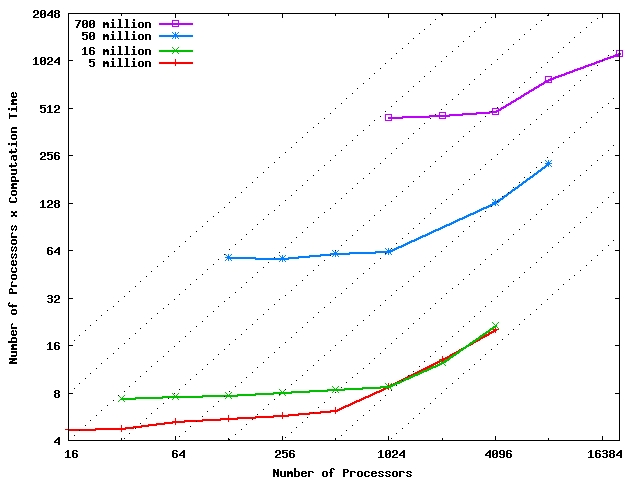 Scaling on BlueGene/L
Scaling on BlueGene/L
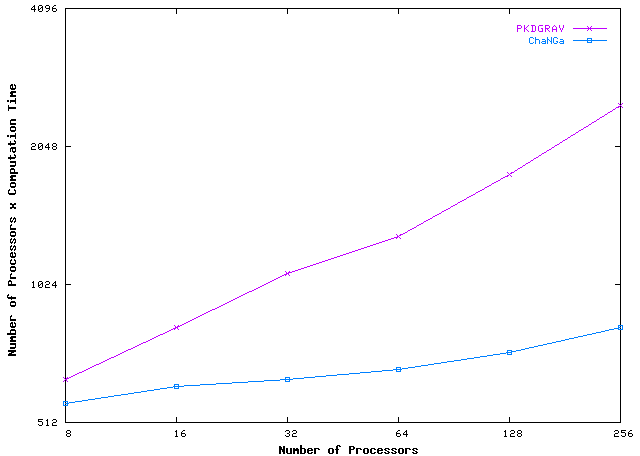 Comparison between ChaNGa and PKDGRAV on Tungsten
Comparison between ChaNGa and PKDGRAV on Tungsten
As a prototype the initial visualizer spreads particles uniformly across all the processors and each processor updated the image data for all the particles resident in it. However this resulted in all processors sending copies of the whole image to the client. This resulted in a lot of data transfer between the visualizer client and the parallel program, apart from slowing down the client. As an optimization the image was decomposed into a tree with the leaves containing data for particles belonging to a certain portion of the image. This allowed each processor to send only a small part of the entire image instead of the whole image. As another optimization, the processors sent texture maps for each portion of the image. This allowed the visualizer to rotate and pan the image without having to wait for data from the processors. Once the data arrives at the visualizer it can be used to update the image. This also saves bandwidth between the processors and the visualizer client.
This project is funded in part by NSF ITR program, via a grant titled: "ITR: Collaborative Research: Advanced Parallel Computing Techniques with Applications to Computational Cosmology."
NChilada
This is a collaborative project with Prof. Thomas Quinn (University of Washington) and Marianne Winslett (University of Illinois), to build NChilada, a framework for enabling N-Body based parallel simulations, and especially those in Cosmology and Astronomy.It Involves various algorithms, with the basic parallel data structure being particles organized into trees (OctTree, ORB, or Space Filling Curve). A common tree abstract is being created to simplify the conversion between tree models, and to provide common interface for various operations on the particles stored in the tree structures. As an example, the user can demand for the neighbors within a given distance for one or all of the particles, and apply a certain calculation on the neighbors.
The algorithm being studied for the force computation uses the typical Barnes-Hut O(nlogn) structure to reduce the amount of computation performed. In order to compute the pair interaction between particles and nodes on different processors, the parts of the tree needed for the computation of a particle are imported from the processor where that particle belongs to. This implies both an explosion of the memory used for large datasets, and the need to structure the import so that the external nodes are transferred only once and used by all the particles which need them. For this reason, a CacheManager has been built, with the functionality of a software cache.
The main structure of the program involves a chare array (called TreePiece) to hold the particle data and the associated tree structures, and a group (called CacheManager) to hold the imported structures. The main control flow of the force computation is expressed in the figure here below.
Processor control flow
The picture represents the workflow inside a single processor. After the computation is started globally, each TreePiece (green box) receives messages to perform its part. The TreePiece splits the total work into local work, which includes interaction with its own portion of the tree, and global work, which includes interaction with the rest of the system. The global work is composed of two stages: prefetching of the needed data, and visit of the tree. During the global work, the TreePiece requests the CacheManager (orange box) for data not locally present. If the data is already buffered, it is immediately returned, otherwise it is requested to another processor. When the data comes back, it is buffered and forwarded to the requesting TreePiece. In order to mask the latency occurring while fetching remote data, the global work is divided into chunks, and the computation is executed in a pipelined fashion. Moreover, the local work is used as an additional source of computation to mask the latency.
After having a basic version of ChaNGa in place, we studied its performance and added a number of optimizations to the code. Some of these optimizations were designed to exploit Charm++ aspects that enable high performance, whereas others were aimed at specific characteristics of particle codes. The current ChaNGa code (with all the optimizations) scales pretty well on large parallel machines like BlueGene/L, IBM HPCx, NCSA Tungsten with real cosmological datasets.
Scaling on BlueGene/L
Comparison between ChaNGa and PKDGRAV on Tungsten
Salsa
Visualization in the context of cosmology involves a huge amount of data, possibly spread over multiple processors. We solve this problem by using a parallel visualizer written in charm++. It uses the client server model in charm to interact with code running on multiple processors. The visualizer allows the user to zoom in and out, pan and rotate the image. This results in update requests being sent from the visualizer code to the parallel programs. A series of optimizations have been carried out to this basic scheme. An example of the visualizer is shown on top of this page.As a prototype the initial visualizer spreads particles uniformly across all the processors and each processor updated the image data for all the particles resident in it. However this resulted in all processors sending copies of the whole image to the client. This resulted in a lot of data transfer between the visualizer client and the parallel program, apart from slowing down the client. As an optimization the image was decomposed into a tree with the leaves containing data for particles belonging to a certain portion of the image. This allowed each processor to send only a small part of the entire image instead of the whole image. As another optimization, the processors sent texture maps for each portion of the image. This allowed the visualizer to rotate and pan the image without having to wait for data from the processors. Once the data arrives at the visualizer it can be used to update the image. This also saves bandwidth between the processors and the visualizer client.
This project is funded in part by NSF ITR program, via a grant titled: "ITR: Collaborative Research: Advanced Parallel Computing Techniques with Applications to Computational Cosmology."
People
Papers/Talks